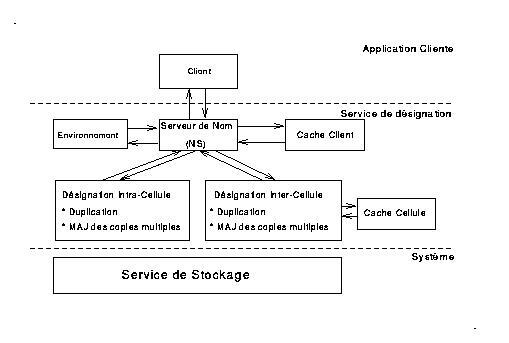
Le service de désignation est une fonction importante du système Guide, il doit permettre aux utilisateurs et aux applications de nommer et d'utiliser leurs objets au moyen de noms symboliques.
Le regroupement des différentes machines connectées au sein d'une même cellule et l'extension à des interconnexions de cellules nécessitent la conception d'un service de désignation global. Un tel service doit à la fois pouvoir contenir un nombre quasiment illimité de machines et d'utilisateurs et résister aux pannes. Le service doit donc répondre à de fortes contraintes de disponibilité et d'efficacité.
Le but de ce chapitre est de présenter le schéma du service de désignation extensible et tolérant les pannes que nous mettrons en oeuvre sur le système Guide.
La fonction de base de la désignation est d'associer aux noms symboliques d'objets leurs identificateurs internes (références système Guide). Pour réaliser cette fonction, on utilise des répertoires dont la structuration permet de construire un espace de noms. Ainsi pour chercher la référence d'un objet désigné par un nom, on doit fournir son chemin d'accès. Un tel chemin est formé par la concaténation des noms des répertoires traversés pour accéder à l'objet.
Pour concevoir un service de désignation extensible, il faut répondre aux objectifs suivants :
Il faut noter que l'extension ne consiste pas simplement en un regroupement d'espaces de noms, elle remet également en question les techniques utilisées pour résister aux pannes et pour assurer l'efficacité des mécanismes.
Le service de désignation est bâti au-dessus du système Guide. L'interface qu'il fournit aux utilisateurs est similaire à celle du système de fichiers d'UNIX. Les noms sont indépendants de la localisation des objets qu'ils désignent, leur recherche s'effectue dans une arborescence unique et globale à un ensemble de cellules Guide.
Un objet serveur de noms est un objet Guide, c'est donc un objet passif. Cependant nous avons gardé l'appellation Serveur (plutôt que service) car cet objet a la même fonction qu'un serveur dans un système classique.
Le service de désignation est sollicité par les différentes applications du système (Programmes Guide, Cyrilnote2 et interpréteurs de commandes), on y accède par création d'une instance de la classe serveurs de noms (Name server). Chaque application exécute donc une instance particulière, cela nous permet d'utiliser les variables de ces instances pour stocker l'environnement du service et son état (par exemple : répertoire par défaut, répertoire de travail, contenu du cache utilisateur).
Le serveur de noms est organisé en deux niveaux :
Les composantes fonctionnelles du service de désignation sont modélisées par des objets, elles seront développées progressivement dans la suite du rapport. Ces composantes sont :
L'interaction entre ces composantes est représentée dans la Fig 0 , le Service de Stockage de Guide constitue la partie système qui gère la persistance des objets. Pour notre application, seule la composante fonctionnelle catalogue doit être persistante. Les autres composantes sont créées et détruites dynamiquement au moment de l'utilisation du service.
L'espace de noms proposé pour le système Guide est une arborescence à base d'objets, elle est unique et globale à un ensemble de cellules interconnectées. L'extension est obtenue par un regroupement par le haut d'un ensemble d'espaces locaux à des cellules . Cette approche permet de regrouper un grand nombre de cellules moyennant peu de répertoires globaux, elle possède aussi l'avantage de préserver la désignation locale à une cellule puisqu'elle ne modifie pas sa structure (voir Lampson ).
La structure de l'espace ainsi obtenue sera formée de deux parties disjointes, la première est la partie supérieure de l'arbre, elle sera qualifiée de niveau global ou inter-cellulaire, la seconde partie correspond au niveau inférieur et sera dite niveau local ou intra-cellulaire.
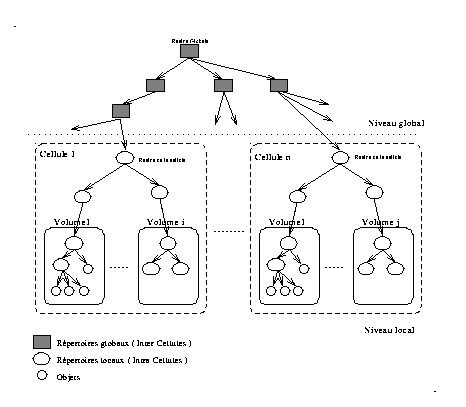
Cette séparation a un impact considérable sur les méthodes de conceptions utilisées dans les deux niveaux, chacun d'eux possède des propriétés particulières et nécessite des mécanismes adaptés. L'autre conséquence concerne la structure des noms absolus globaux qui sont composés de deux parties :
Des conventions de nommage ont été prises pour accélérer la recherche de noms et pour bien spécifier ses règles d'utilisation. Elle définissent la manière d'écrire les noms dans les applications et l'état du service, à l'initialisation et au cours de son utilisation. Les conventions prises sont :
ex : %Grenoble/IMAG/Bull-IMAG/users/layaida
Les répertoires locaux à une cellule sont implantés par des objets Catalog, leur rôle consiste à maintenir l'association entre des noms symboliques simples et des références d'objets. L'espace de noms local est construit par un chaînage de ces répertoires, ils sont définis par le type suivant :
TYPE Catalog IS
// Nom simple du catalogue
Name : String;
// Pointeur vers le répertoire père
Father : REF Catalog;
// Pointeur vers la racine locale
Root : REF Catalog;
// liste des entrées du catalogue
List_Entries : List OF Association;
// Taille des Entrées du catalogue
Size : Integer;
// Liste des copies du catalogue
CatalCopies : List OF REF Catalog;
// Nombre de copies du catalogue
NbrCopies : Integer;
END Catalog.
Cette structure du répertoire définit l'espace primitif de désignation, le chaînage de ces répertoires permet aux serveurs de noms de naviguer dans l'arborescence avec les opérations (méthodes) de changement de répertoire. Au niveau logique, il n'y a qu'un seul répertoire pour un nom absolu donné mais en réalité l'espace est dupliqué.
Les entrées des répertoires sont implantées par des enregistrements de type association qui sont de deux types :
SYNONYM Association = Record
Name : String;
Date : Integer;
Copies : List OF REF Catalog;
NbrCopies : Integer;
END;
SYNONYM Association = Record
Name : String;
Type : REF Top;
Date : Integer;
Oid : REF Top;
END;
SYNONYM Association = Record
Name : String;
Date : Integer;
Symbolic_Link : REF Path;
END;
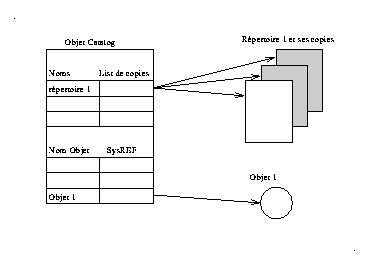
Le service de désignation est au coeur du système, sa disponibilité est un facteur critique pour le fonctionnement des applications. Le choix de gérer la duplication des répertoires et de déléguer celle des autres objets au système est très important dans notre conception. Les répertoires étant un moyen d'accès, leur disponibilité est indispensable. En plus de cet aspect, les stratégies de tolérance aux pannes nécessitent un contrôle sur le placement des copies ainsi que sur leur nombre. Ce nombre varie en fonction de l'importance du répertoire qui est d'autant plus élevé que l'on se rapproche de la racine.
Les répertoires globaux visent essentiellement à regrouper les espaces de noms disjoints contenus dans les différentes cellules du système. L'accès aux répertoires d'une cellule distante se fait par l'intermédiaire d'une désignation primitive étendue à l'échelle inter-cellulaire.
Dans l'état actuel du système, le bit de poids le plus élevé d'une référence système indique si l'objet est local ou non. Dans le cadre de notre projet, nous utiliserons pour chaque entrée des objets Global_Catalog un champ indiquant la cellule où se trouve l'objet correspondant.
Les opérations appliquées sur les répertoires globaux sont en apparence les mêmes que celles des répertoires locaux. En réalité elles peuvent nécessiter des informations systèmes qui ne sont connues que par l'administrateur. Un exemple typique est la création d'une nouvelle racine regroupant des espaces disjoints (voir section .4.3). Vues les conséquences de ces manipulations, les opérations sur les répertoires globaux doivent être considérées comme privilégiées et réservées à l'administration du système.
Les répertoires locaux sont implantés par le type Catalog. Le principe d'un répertoire est simple, c'est une table de correspondance entre des noms simples et des références d'objets. Ces objets sont de deux types : objets Catalog et les objets d'un autre type. Pour les objets les opérations consistent à ajouter, enlever ou chercher l'association entre un nom simple et sa référence système. Pour les objets Catalog l'opération consiste à créer, enlever ou changer de répertoire. Il faut noter que les opérations de mise à jour sont faites sur un espace de noms dupliqué, il est donc essentiel des les synchroniser (voir section 5.4.1).
Ces opérations sont implantées par les méthodes suivantes :
TYPE Catalog IS
METHOD AddEntry();
METHOD RemoveEntry();
METHOD SearchEntry();
METHOD CreateDir();
METHOD RemoveDir();
METHOD SearchDir();
METHOD ChangeDir();
METHOD ListPrint();
END Catalog.
Le serveur de noms constitue l'interface entre les applications et le service de répertoires. Il est réalisé au moyen de la classe NameServer qui implante les opérations de recherche de noms, il est décrit par le type suivant :
TYPE NameServer IS
Boot_Object : REf Boot ;
Local_Root : REF Catalog;
Global_Root : REF Global_Catalog;
CurrentPath : REF Path;
CurrentCatalog : REF Top;
Working_Catalog: REF Catalog;
Working_Path : REF Path;
UserCache : REF User_Cache;
GlobalCache : REF Global_Cache;
END NameServer.
Ces différentes variables définissent l'état du serveur, elles sont initialisées pendant la création d'une instance de type NameServer. Les valeurs de ces variables sont ensuite modifiées au cours de l'utilisation du serveur par les opérations fournies aux utilisateurs et à l'administration du système.
La référence du cache global (Global_Cache) est également retrouvée à l'initialisation, le cache utilisateur est créé et son contenu est vide au départ.
L'ensemble de ces opérations est réalisé au moyen d'un appel à la méthode Init de l'objet serveur de noms.
Le service de désignation a besoin de retrouver des informations pour établir sa liaison avec l'espace de noms du système, cette opération se fait par l'intermédiaire d'une table système implantée par l'objet boot. Le contenu de cet objet est représenté dans la Fig 3 .
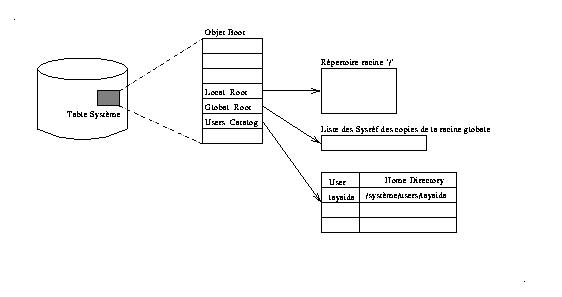
Le répertoire /users est un objet particulier où l'on enregistre les différents utilisateurs du système, il permet de retrouver le répertoire de travail lorsqu'une instance du service est créée. D'autres opérations sont prévues pour enregistrer ou supprimer des utilisateurs dans le système.
La cohérence de la liste contenant la référence de la racine globale et de ses copies est laissée à la charge du système. On supposera que cette liste est maintenue à jour par un protocole de diffusion inter-cellules, la fiabilité de cette opération peut être relâchée car le changement progressif de la racine globale ne gêne pas le fonctionnement du service de désignation. Le protocole d'échange de tables systèmes entre les sites permet la mise à jour des objets boot de chaque site. Ce protocole est décrit en détail dans le papier d'administration du système Guide .
L'objet boot est consulté et mis à jour par les méthodes suivantes :
TYPE Boot IS
METHOD Init();
METHOD Get_Local_Root : REF Catalog;
METHOD Get_Global_Root:LIST OF REF Global_Catalog;
METHOD Get_Global_Cache: REF Global_Cache;
METHOD Add_User(IN User_Id,Home_Dir);
METHOD Delete_User (IN User_Id ): Boolean;
METHOD Get_Home_Dir(IN User_Id ): REF Path;
END Boot.
Les opérations sur les répertoires ne manipulent que les noms simples. Au niveau serveur cette notion est étendue aux noms de chemins. Un client peut désigner un objet en indiquant son chemin d'accès et c'est le serveur qui se charge de le retrouver. Cette opération de recherche utilise l'espace de noms dupliqué pour trouver au moins une copie accessible.
L'opération de désignation la plus utilisée dans le serveur est la résolution de noms (Look_Up), elle est appelée par toutes les autres opérations et consiste à retrouver la Sysref correspondant à un nom absolu. Nous allons décrire les paramètres qu'elle fournit au serveur et leur utilité :
METHOD Look_Up
( IN Pathname : REF Path;
OUT Global_Prefix : REF Path;
Global_Cat : REF Global_Catalog;
Local_Prefix : REF Path;
Local_Cat : REF Catalog ): REF Top;
Les paramètres en sortie permettent de remplir progressivement le contenu des caches de noms (voir section 6). Le résultat de cette opération est une référence de type Top, il est le type générique du langage Guide, il permet d'englober tous les autres types et donc de référencer l'ensemble des objets.
Les autres opérations fournies par le service sont les mêmes que celles rencontrées dans les interpréteurs de commandes ( ls, mkdir, rmdir etc ..), une fois le Look_Up mis au point, leur réalisation ne présente pas de difficultés.
Les services d'administration sont réalisés par des opérations particulières, elles concernent la manipulation des répertoires globaux et donc de la mise en oeuvre des mécanismes d'extension. Il y a deux types d'opérations :
Dans les deux cas, le problème posé est de garantir la validité des anciens noms après cette modification de la structure de l'arbre, le premier cas est simple et consiste à ajouter un lien symbolique de poursuite vers le nouvel emplacement, nous l'avons implanté par la méthode suivante :
METHOD Move(IN Origin_Path; Dest_Path): Boolean;
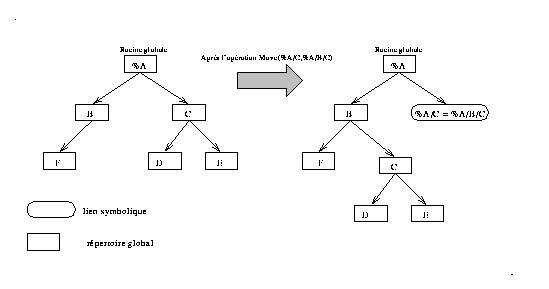
Le deuxième cas est plus complexe : après la création d'une nouvelle racine, les noms symboliques absolus lui seront systématiquement envoyés, les anciens noms ne sont donc plus valides.
Pour résoudre ce problème nous allons utiliser la méthode proposée par Lampson , elle consiste à utiliser des identificateurs uniques de répertoires pour garder trace des changements de racine. Chaque nom absolu est préfixé par l'identificateur de la racine courante. Pour retrouver le bon répertoire, la nouvelle racine maintient une table d'association entre ces identificateurs et leur nouveau préfixe (voire l'exemple de la Fig 5 ).
La création d'une nouvelle racine globale est réalisée au moyen de la méthode suivante :
METHOD New_Root(IN Root1, Root2 : REF Global_Catalog);

L'exemple de la figure représente la création d'une nouvelle racine, un nom comme %B/obj sera remplacé par %A/B/obj en passant par la nouvelle racine A.
Dans le cas de notre réalisation, l'identification unique est déjà fournie par le système ( ie. les références systèmes ), mais pour un répertoire donné il en existe plusieurs puisque l'espace de noms est dupliqué. Nous avons choisi de prendre la référence du premier répertoire créé pour servir d'identificateur.
Le service de désignation étant le moyen d'accès aux objets, il doit en assurer l'accès en présence de pannes. Dans les systèmes de grande taille, la probabilité de ces pannes est importante, il faut donc définir une stratégie pour assurer la continuité du service.
Notre approche pour résoudre ce problème consiste d'une part à améliorer la disponibilité moyennant la duplication, et d'autre part à améliorer l'autonomie de chaque niveau du système ( cellule, site et volume ).
Les pannes du système Guide peuvent survenir à n'importe quel moment de son fonctionnement. L'architecture générale du système étant formé pas une interconnexion de cellules, les sources de pannes peuvent provenir de plusieurs endroits. Le service de désignation sera considéré en fonctionnement dégradé dans les cas suivants :
Les sources de pannes sont variées, mais au niveau de notre application nous allons ramener ce problème à un appel de méthode qui teste la présence d'un objet. Nous utiliserons pour l'implantation de cette méthode les mécanismes d'exception fournis par le langage Guide .
Le principe de l'utilisation des exceptions consiste à récupérer le contrôle dans l'objet appelant après la détection d'une panne, ce contrôle est mis en oeuvre par un traitant associé à chaque type de panne. La seule panne considérée au niveau du langage est l'appel à un objet non disponible, sa reprise permet au moment de la résolution de noms de trouver une copie accessible.
La résolution des noms absolus dans les services de désignation se fait par recherches successives dans les répertoires formant leurs chaînes d'accès. Dans les systèmes distribués les répertoires en question peuvent se trouver sur des sites différents et la panne de l'un d'entre eux rend inaccessible l'objet recherché. Pour éviter l'effet de telles pannes on a recours à la duplication de répertoires qui contribue aussi à l'amélioration de l'efficacité en augmentant le degré de parallélisme d'accès aux répertoires.
Le mécanisme de duplication est mis en oeuvre à deux niveaux : le niveau inter-cellule et intra-cellule. Cette séparation est dûe à la différence qu'il y a entre le degré de couplage entre les répertoires du niveau local et ceux du niveau global. Chaque niveau nécessite donc des algorithmes de duplication et de synchronisation de copies adaptés.
Une question importante est de savoir le coût introduit par les algorithmes de duplication, ainsi que l'impact de cette duplication sur les mécanismes de recherche de noms. On s'intéresse dans une première étape à la nature de ces coûts évalués selon deux grandeurs :
Le coût des algorithmes de recherche de noms sur un espace de noms dupliqué sera abordé au paragraphe qui traite des mécanismes de recherche de noms. Le coût est généralement plus élevé pour les opérations de création de répertoires et de leur mise à jour, il faut alors le limiter le plus possible.
Pour réaliser une stratégie de tolérance aux pannes, les algorithmes de duplication nécessitent un contrôle du placement des copies sur l'espace de stockage du système. Des primitives ont été créées au niveau du noyau de Guide 1 pour réaliser ce contrôle; dans notre maquette on a utilisé un objet Contrôleur dont l'intérêt est de pouvoir fournir une interface standard qui permettra de porter ce travail sur Guide-2. Il est implanté par le type suivant :
TYPE Controler IS
METHOD Init;
METHOD Get_Vol_Id(IN REF Top ): Vol_Id ;
METHOD Get_Site_Id(IN REF Top ): Site_Id ;
METHOD Get_Cell_Id(IN REF Top ): Cell_Id ;
METHOD Create_Copy(IN Cell_Id;IN REF Top):REF Top;
METHOD Create_Copy(IN Site_Id;IN REF Top):REF Top;
METHOD Create_Copy(IN Vol_Id;IN REF Top): REF Top;
END Controler.
Les méthodes Get_Vol_Id, Get_Site_Id et Get_Cell_Id permettent de récupérer à partir d'une référence système des informations sur la localité des objets au niveau du volume du site ou de la cellule du système. Dans le cas de Guide cela se résume à examiner la structure de la référence qui contient ces informations.
La méthode Create_Copy permet de créer des copies d'objets à différents niveaux du système, pour l'implanter nous avons modifié la méthode de création d'instances d'objets MetaClass.New pour la paramétrer en fonction de l'endroit de création désiré et de sa granularité : cellule, site ou volume. L'objet Controler sera utilisé comme outil de base de la duplication de répertoires.
L'algorithme de duplication proposé utilise les méthodes de l'objet contrôleur, le principe est de recopier toutes les chaînes d'accès aux objets créés localement.
Algorithme : duplication intra-Cellule
Pour Chaque objet créé ( Obj ):
Volume = Volume (Obj);
Pour chaque répertoire Rep du chemin d'accès
OidRep = SysRef (Rep);
Si Volume not in \{Volume(List_Copies (OidRep))\}
Alors Oid_copie:=CréerCopie(Volume, OidRep);
Insérer (Oid_Copie, Rep(i));
Fsi;
Rep := Succ(Path);
Fin_Pour.
Fin.
La fonction Volume prend comme paramètre une liste de références internes, elle retourne la liste des volumes de stockage des objets correspondants.
La fonction List_Copies permet de retrouver la liste des copies d'un répertoire à partir de sa référence interne.
Cet algorithme réalise une duplication qui vise plusieurs objectifs, nous allons montrer qu'il aboutit effectivement à un degré de résistance aux pannes appréciable et que le coût de la duplication en espace de stockage reste raisonnable. Cet algorithme présente les propriétés suivantes :
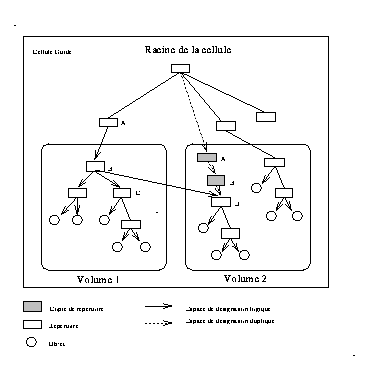
Fig 6. Exemple d'application de l'algorithme pour la création du répertoire /A/B/D
Il est important de noter que la politique de placement des objets sur les volumes est totalement à la charge du système. Le service de désignation ne possède le contrôle que sur les copies de répertoires. La création d'un nouveau répertoire, du point de vue du service de désignation, peut se faire dans n'importe quel volume. Cette stratégie garantie l'indépendance de notre application par rapport au niveau système.
La duplication à ce niveau tient compte des critères suivants :
Pour créer un répertoire global, l'utilisateur doit spécifier le niveau de tolérance aux pannes qu'il souhaite avoir. En pratique, nous avons retenu l'idée du système GALAXY, elle consiste à paramètrer la méthode de création d'un répertoire avec le nombre de chemins distincts permettant d'y accéder.
Algorithme : duplication inter-cellules
Entrée : List_Cell : List OF Cell;
Path : REF Path;
k_Path : Integer;
Debut
Rep := Global_Root;
Pour chaque répertoire du chemin d'accès (path)
Si NbrCopies( Rep ) < k_Path
Alors
Pour j:=1jusqu'a(k_Path-NbrCopies(Rep))+1
c:={cinList_Cell vee cnot inCell(Copies(Rep))};
copie := Create_Copy( c, Rep);
Insert_Copy ( copie, Copies(Rep));
Fin_Pour;
Rep := Succ(Path);
Fin_Pour.
Fin.
Dans cet algorithme, on fournit en entrée les paramètres suivants :
List_Cell : c'est la liste des cellules formant le système Guide, elle est mise à jour et fournie par l'administration du système.
Path : ce paramètre indique le chemin d'accès du répertoire en cours de création, il est composé uniquement de répertoires globaux.
k-Path : c'est le nombre de chemins distincts que l'on veut avoir pour accèder au répertoire créé.
Les procédures utilisées ont la sémantique suivante :
NbrCopies(Rep) : Nombre de copies d'un répertoire Rep donné.
Cell(Copies(Rep)) : Ensemble des cellules contenant les copies d'un répertoire Rep donné.
Insert_Copy(copie, Copies(Rep)) : insertion d'une nouvelle copie de Rep et mise à jour des chaînages.
L'algorithme consiste à parcourir le chemin d'accès au répertoire à partir de la racine globale, et de s'assurer que pour chaque répertoire il existe au moins k_path copies placées sur des cellules différentes.
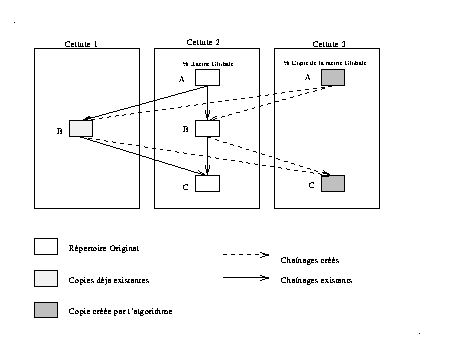
Fig 7. Exemple de création du répertoire /A/B/C ( avec 2-chemin résistant)
Dans l'exemple de la Fig 7 , après une demande de création du répertoire C avec k_path égal à deux, l'algorithme a dupliqué le chemin d'accès en créant une nouvelle copie de la racine globale %A et deux copies du répertoire %A/B/C , notons qu'il n'a pas eu besoin de dupliquer le répertoire %A/B puisque deux copies étaient déjà disponibles.
Un répertoire dupliqué peut logiquement être vu comme un objet unique. Si un changement a lieu sur l'une de ses copies toutes les autres doivent être mises à jour. Le problème qui se pose est de garantir que ces changements se fassent sur toutes les copies (atomicité)et dans le même ordre (sérialisation).
Le problème du couplage des copies nécessite de réaliser une stratégie de mise à jour à deux niveaux :
Pour résoudre ce problème au niveau local, nous utilisons le principe de la copie primaire (généralement c'est la copie originale d'un répertoire ). Les requêtes de modification lui sont d'abord envoyées et celle-ci se charge de les propager sur l'ensemble des copies. Si une partie des copies n'est pas accessible, on effectue quand même les modifications sur les répertoires présents et on diffère la mise à jour des copies inaccessibles, l'algorithme est le suivant :
Algorithme : mise à jour des répertoires locaux
Entrée : Rep : REF Catalog ;
Operation : Record
Operation : String;
Arguments : String;
End;
Debut
Master_Copy := Rep.Copie(0);
Nbr_Copies := Rep.NbrCopies;
Si Master_Copy.Present
Alors
Pour i:=1 jusqu'a Nbr_Copies
Si Copie(i).Present
Alors
Copie(i).Operation(Arguments)
Sinon
Register(i,Operation,Arguments)
Fin_Pour;
Fin_Si;
Fin.
Ce principe est mis en oeuvre au niveau de la copie primaire qui garde, à son niveau, une trace de toutes les opérations différées. Cette approche engendre une dissymétrie de l'espace dupliqué : le rôle des copies primaires étant plus important que celui du reste des répertoires. Il devient alors nécessaire de pouvoir stocker ces copies primaires de manière à assurer leur disponibilité . Le système Guide a prévu pour sa politique de stockage des serveurs Goofy de type fiable, ils seront utilisés à cet effet.
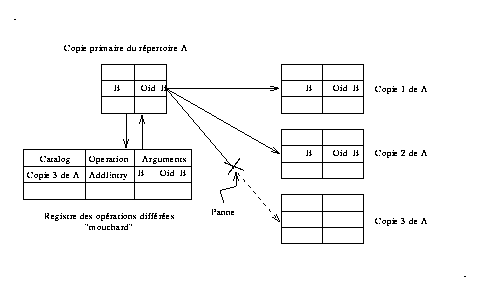
Cet exemple illustre une opération de mise à jour du répertoire A par l'adjonction d'une nouvelle entrée ( B, Oid_B). La copie 3 n'étant pas accessible, on reporte sa mise à jour en l'enregistrant sur le registre de la copie primaire, une fois que la copie 3 sera redevenue accessible l'opération sera effectuée. Pour garantir la sérialisation des modifications sur les répertoires le registre est organisé en file FIFO.
Au niveau global on a choisi de faire une mise à jour périodique des copies, cette opération est réservée aux administrateurs de l'espace de désignation.
Cette mise à jour repose sur un mécanisme d'estampilles associée a chaque entrée d'un répertoire global. Chaque administrateur ne modifie que la copie dont il a la charge, ainsi les copies peuvent avoir un contenu différent. Pour synchroniser ces copies l'administrateur dispose de deux opérations qui sont elles mêmes estampillées :
Les modifications étant rares à ce niveau, cette approche est satisfaisante. En plus la probabilité de collision de noms est minime puisque ces manipulations sont faites par un personnel compétent. L'autre avantage est l'amélioration de la concurrence : chaque administrateur voit immédiatement les modifications qu'il apporte à sa copie, l'inconvénient est que le signalement d'une collision de noms est différé. Cette méthode est utilisée dans le système décrit par Lampson .
Les systèmes bâtis sur UNIX ont été initialement conçus d'une manière centralisée, les mécanismes de répartition ont été ajoutés au niveau supérieur du système par conséquent ils jouissent d'une grande autonomie de fonctionnement. Par opposition, les systèmes dont la conception est fondamentalement répartie ont une autonomie très limitée sinon inexistante. Dans le cas du système Guide, la panne d'un support de stockage risque de rendre inaccessible un ensemble quelconque de catalogues et de réduire d'une manière aléatoire l'espace de noms utilisable.
L'autonomie est un critère important dans les systèmes extensibles, elle permet l'utilisation d'une partie isolée du système et limite les effets d'une panne. Chaque niveau du système doit pouvoir fonctionner d'une manière autonome et faire le moins possible appel aux répertoires distants. Pour pouvoir mettre en oeuvre cette autonomie nous avons introduit des modes de fonctionnement du service :
Le fait que les répertoires globaux ne fournissent qu'une connexion au monde extérieur à une cellule, la panne du service au niveau inter-cellule ne compromet pas le fonctionnement local du service de désignation. Un tel cas intervient lorsque la ligne de communication reliant la cellule au réseau extérieur n'est plus en fonctionnement ou que la racine globale n'est pas accessible.
L'autonomie d'une cellule est assurée par l'unicité de la racine de l'espace de noms local, cette racine est implantée par un catalogue particulier désigné par le symbole `/` et qui est accessible par tous les sites du système.
Un site est une machine quelconque dotée du système Guide et d'un disque de stockage. L'autonomie du site est mise en oeuvre par l'algorithme de duplication des répertoires, il recopie toutes les chaînes d'accès aux répertoires contenus dans ses volumes. Les algorithmes de recherche de noms se limitent à consulter les copies locales de répertoires, pour accélérer cette opération, la copie locale est la première consultée.
Les caches de noms sont mis en oeuvre pour améliorer l'efficacité du service en profitant de la propriété de localité des références. En plus de cet aspect, les caches de noms contribuent sensiblement à l'extensibilité du système pour les raisons suivantes :
L'opération de recherche dans le cache consiste à retrouver le plus long préfixe qui corresponde au chemin d'accès, le résultat d'une telle recherche peut être de trois types :
Dans les systèmes hiérarchiques, la recherche de noms commence généralement par la racine globale jusqu'aux répertoires locaux. Cette recherche est très coûteuse car elle nous oblige à traverser des cellules et des sites distants, il est alors intéressant de garder temporairement l'association entre le nom symbolique et sa référence système localement. Dans cette réalisation, notre choix s'est porté sur deux types de caches : un pour l'utilisateur et un deuxième global à une cellule, ce choix à été motivé par les avantages suivants :
Le cache utilisateur est une table qui peut contenir dix répertoires, cette table maintient l'association entre un nom absolu de répertoires et son contenu. Ainsi, l'opération de Look_Up examine d'abord le contenu de cette table avant d'entreprendre une recherche à partir de la racine, si le nom est résolu le résultat est immédiat, dans le cas contraire ( cas d' échec ou de succès partiel ) un nouveau parcours de l'arbre est nécessaire.
La politique de gestion du cache est LRU (last reacently used), avec une invalidation supplémentaire si la référence fournie par le cache s'avère obsolète. La validité des références est donc vérifiée au moment de l'accès. Cette propriété est caractéristique des répertoires, elle nous permet d'améliorer l'efficacité sans porter atteinte à la cohérence des répertoires .
Le cache utilisateur est créé à l'initialisation du serveur de noms, il se remplit au fur et à mesure des opérations de Look_Up. Des études expérimentales (voire K.W Shirrif ) sur le comportement des caches prévoient une stabilisation rapide de son contenu, c'est dû à la localité des noms utilisés par les applications. Ce cache est implanté par la classe suivante :
TYPE Cache_Local IS
METHOD Init;
METHOD Look_In_Cache();
METHOD Insert_In_Cache;
METHOD Test_Cache_Full : Boolean;
METHOD LRU_Replace();
METHOD Entry_Invalidate();
METHOD List_Cache();
END Cache_local.
Ces différentes méthodes sont combinées aux algorithmes de recherche pour améliorer leur temps de réponse.
Un cache au niveau de la cellule est mis en place pour réduire le coût de la recherche inter-cellules, cette dernière fait appel à des répertoires globaux dont l'accès est relativement coûteux. Cette propriété intervient aussi dans le choix de la politique de gestion du cache.
La politique de cohérence la mieux adaptée est celle qui utilise les dates d'expiration, elle consiste à associer à chaque répertoire du cache une date de validité. Dès que cette date est dépassée le répertoire est invalidé. Au niveau de l'implantation, le cache global est similaire au cache local, sauf pour la méthode d'invalidation.
Le choix d'utiliser un seul cache pour toute la cellule a été motivé par deux objectifs : d'une part faire profiter tous les utilisateurs de la cellule de ces informations coûteuses, et d'autre part alléger la charge d'accès aux répertoires inter-cellules.
Une cellule est un regroupement de machines Guide avec un réseau local
(2) (3)Ce terme désigne les répertoires partagés par un ensemble de cellules