
Lors de son utilisation, un système informatique peut être sujet à de multiples défaillances telles que : la panne d'un site, la panne d'un disque ou le partitionnement du réseau. Le traitement des pannes doit donc être pris en compte dans la conception du système afin d'assurer la continuité du service. La taille du système peut augmenter par ajout de nouvelles cellules et de nouveaux sites, ce qui entraîne une probabilité croissante d'avoir un ou plusieurs composants du système en panne. En conséquence, il faut s'efforcer de réduire l'effet des pannes sur le service de désignation uniquement aux machines directement touchées.
Deux techniques sont utilisées pour mettre en oeuvre une stratégie de tolérance aux pannes efficace :
La duplication peut être de deux types : soit totale, soit partielle, avec dans les deux cas des politiques de cohérence diverses.
La duplication de tout le service de désignation est l'une des manières d'assurer la disponibilité du service. Si l'un des sites contenant une copie du service tombe en panne, les demandes de service utiliseront l'une des autres copies accessibles. Cette technique présente les deux inconvénients suivants :
Le serveur de noms d'Amoeba est constitué d'un serveur dupliqué à deux exemplaires. Chaque serveur communique avec deux serveurs de stockage qui utilisent des supports de stockage distincts, au moyen de chemins indépendants (cf. Fig 0 ).
Une demande de modification ayant été demandée à l'un des serveurs, celui-ci l'effectue en mémoire et sur son serveur de stockage principal, puis il communique la modification à l'autre serveur de noms. Ces trois opérations sont réalisées dans une transaction. Le deuxième serveur effectue la mise à jour de sa copie en mémoire, et chaîne la modification dans une file qui est servie par un processus fonctionnant en tâche de fond, et qui effectue la mise à jour sur l'autre serveur de stockage.
Fig 0. Serveurs de répertoires d'Amoeba
Dans les systèmes utilisant des espaces de noms hiérarchiques, la résolution d'un nom absolu nécessite une recherche séquentielle dans les différents répertoires qui le composent. En général, la résolution d'un nom qui possède n éléments fait intervenir n-1 répertoires, le site de résidence de l'objet est appelé site gérant.
Dans un système centralisé, tous les répertoires sont locaux et l'intérêt aux aspects de tolérance aux pannes est limité. En revanche, dans les systèmes distribués utilisant un espace de noms réparti, les n-1 répertoires du chemin d'accès peuvent se trouver sur des sites, des volumes ou des cellules distincts (cf Fig 1 ). Le succès de l'opération de résolution dépend alors de la disponibilité de ces sites, car la panne de l'un d'entre eux risque d'interrompre l'interprétation de cette chaîne d'accès.
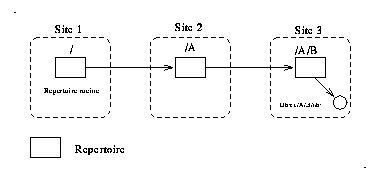
Fig 1. Recherche de noms distribuée
Étant donné un objet quelconque du système, la robustesse de l'opération de résolution de son nom dépend de l'emplacement des répertoires (originaux ou copies) qui composent son chemin d'accès.
A partir des différentes manières de réaliser ce placement sur les sites du système, nous allons définir un ensemble de facteurs qui conditionnent le degré de tolérance aux pannes des mécanismes de résolution de noms.
Définition : La distance du sous-chemin est un entier qui caractérise une paire (Site, nom absolu), il mesure le nombre de répertoires successifs à partir de la racine qui sont locaux au site initiateur de l'opération de résolution.
Cette grandeur fournit une indication sur le degré d'autonomie du site, ce dernier n'ayant pas besoin de consulter de répertoires distants pendant la résolution du sous-chemin.
Pour améliorer la tolérance aux pannes, il faut augmenter la valeur moyenne des sous-chemins du système. L'exemple de la Fig 2 montre que pour la paire (/a/b/c/d, site1) la distance du sous-chemin vaut trois, alors que pour la paire (/a/e, site2) la distance du sous-chemin n'est que de un.
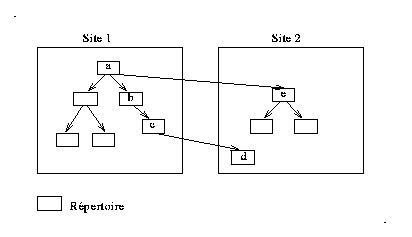
Fig 2. Exemple de distance du sous-chemin
Définition : Une opération de résolution de noms est dite m-étapes fragile si m étapes sur des sites différents sont nécessaires à son achèvement.
Une étape de résolution est définie comme étant le passage d'une partie du nom de chemin entre deux sites.
Le caractère m-étapes fragile d'une opération de résolution d'un nom donné dépend du nombre de copies locales successives formant sa chaîne d'accès ( voir Fig 3 ), plus le nombre est grand plus la probabilité de le résoudre localement augmente.
Si le nom absolu d'un objet contient n composantes alors dans le pire des cas le nombre d'étapes nécessaires à sa résolution est de n-1, ce cas se présente quand seule la racine est présente sur le site du client et que pour chaque répertoire du chemin d'accès, le répertoire suivant n'est pas sur le même site.
Notons qu'une étape supplémentaire peut être nécessaire pour l'accès effectif à l'objet à partir du dernier répertoire si celui-ci n'est pas stocké sur le même site ( ligne dessinée en pointillés sur la Fig 3 ), cette dernière étape n'est pas prise en compte car elle ne fait pas partie du processus de résolution du nom.
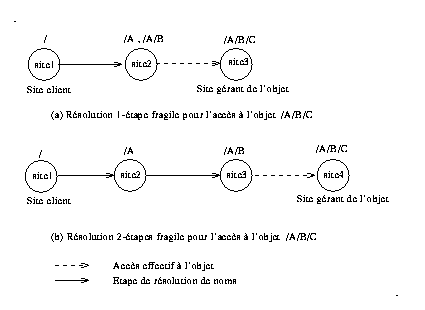
Fig 3. m-étapes fragilité ( m-stage unreliability )
Définition : Une opération de résolution de noms est dite k-chemin résistante si entre deux répertoires consécutifs du chemin d'accès on peut trouver k chemins physiques distincts partant de la racine de l'espace de noms.
Notons que le terme chemin d'accès correspond ici à la structure logique du nom (l'ensemble des copies d'un répertoire sont vues au niveau logique comme un seul répertoire). Il n'y a donc qu'un seul chemin logique pour un nom absolu et plusieurs chemins physiques du point de vue du réseau de communication.
Ce facteur est un bon indice du niveau de tolérance aux pannes du réseau de communication. La valeur de k dépend du degré de duplication des répertoires et de la stratégie de leur placement sur les sites du système.
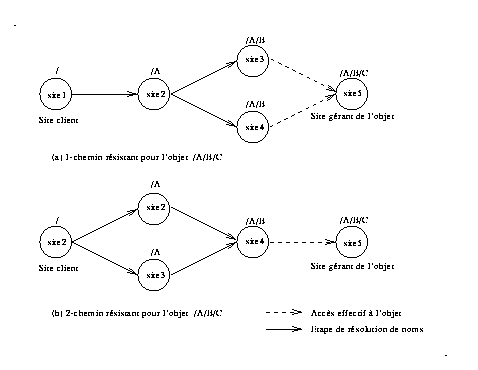
Fig 4. Exemples de k-chemin résistance
Dans cette section nous allons définir des niveaux de tolérance aux pannes à partir des facteurs introduits dans la section précédente :
Racine Résistance : c'est le cas des systèmes qui dupliquent sur tous les sites la racine de l'espace de noms ( sous-chemin >= 1).
Ce cas est très fréquent dans les systèmes d'exploitation existants, il permet d'avoir un accès fiable à la racine de l'espace de noms. La robustesse peut être améliorée en augmentant la valeur moyenne du sous-chemin, on encourage ainsi la duplication des répertoires supérieurs de l'arbre de désignation.
ABMA-Résistance ( All But Manager Access ) : l'accès à un objet est dit ABMA-Résistant si la seule combinaison de fautes qui peut mener à son échec est la panne du site gérant de l'objet.
Cette définition est applicable aux modèles de systèmes où l'objet réside sur le même site que son gérant. La résolution ABMA-résistante pour une paire (site, nom absolu) garantit que si l'objet est accessible alors son chemin d'accès peut certainement être résolu.
La stratégie de duplication mise en oeuvre pour atteindre ce niveau de tolérance aux pannes fait que le site initiateur et le site gérant détiennent au moins une copie des répertoires du chemin d'accès. On obtient de cette façon une résistance aux pannes similaire à celles des systèmes centralisés.
Le système GALAXY a accordé un grand intérêt à la réalisation d'un service de désignation tolérant aux pannes, il utilise les facteurs définis précédemment comme paramètres des algorithmes de duplication, ces algorithmes réalisent un niveau de résistance aux pannes spécifié par les utilisateurs du système. La granularité de la tolérance est appliquée aux chemins, elle n'est donc pas globale. Ce choix est dû à l'importance de certains répertoires par rapport à d'autres (répertoires contenant les binaires par exemple). Les primitives suivantes sont fournies aux utilisateurs :
Cette primitive est utilisée par les utilisateurs pour définir le groupe de sites (nodes) sur lesquelles ils veulent appliquer les algorithmes de duplication. Une valeur particulière All-nodes est utilisée pour définir tous les noeuds du système.
le paramètre nodes_id désigne la liste des sites à partir desquels l'utilisateur souhaite réaliser l'accès à ses objets et pathname en est le chemin d'accès, les autres paramètres décrivent le niveau de tolérance aux pannes souhaité.
Le principe des algorithmes est simple, les répertoires du chemin d'accès sont dupliqués sur des sites spécifiques selon les critères définis par l'utilisateur. Pour gérer les opérations de création et de destruction de copies d'un répertoire, chacun est doté de deux champs :
La cohérence des copies de répertoires vise a rendre transparente aux utilisateurs la duplication de l'espace de noms. L'interface offerte par le service manipule donc des objets logiques. Au niveau du stockage le service manipule des objets physiques qui correspondent aux différentes copies des répertoires. Si un changement a lieu sur un répertoire, toutes ses copies doivent être mises à jour. Un répertoire est dit consistent si, à un instant donné, toutes ses copies sont identiques.
Dans les systèmes répartis, les approches de la cohérence des répertoires sont classées selon trois approches (pessimistes, optimistes et copie primaire), elles sont choisies en fonction de deux critères :
Les approchent pessimistes visent à maintenir une cohérence forte entre les copies de répertoires, elles utilisent généralement les mêmes techniques que celles appliquées aux fichiers, on présente ici quelques exemples :
Ces protocoles utilisent pour la plupart des mécanismes tels que les transactions, le vote ou l'ordonnancement global. Bien que leur mise en oeuvre reste envisageable au sein d'une cellule, elles sont inapplicables au niveau global.
Une autre approche tirant profit des caractéristiques propres aux répertoires est décrite dans Xiaohua , sa mise en oeuvre est complexe car la granularité de la duplication n'est plus le répertoire mais les entrées.
Cette approche est moins restrictive que la précédente, elle consiste à envoyer les modifications vers une copie particulière (la copie primaire) qui se charge de les propager vers le reste des copies.
Le problème de la sérialisation des mises à jour ne se pose pas dans ce cas, l'ordre est défini par les dates d'arrivées des mises à jour au niveau de la copie primaire. Par conséquent, l'aboutissement de ces mises à jour nécessite uniquement la disponibilité de cette copie primaire, les mises à jour qui ne sont pas effectuées sur une copie en raison d'une panne sont enregistrées sur un mouchard (log), elles seront exécutées quand le site de résidence redevient actif. Ces mises à jour sont effectuées de deux manières :
L'inconvénient de l'approche par copie primaire est la responsabilité laissée à sa charge du primaire, car les mises à jour dépendent de sa disponibilité. Une variante consiste à lancer l'élection d'une nouvelle copie primaire si la première devient inaccessible, on introduit alors le risque de ne pas prendre en compte les mises à jour reportées dans le mouchard de l'ancienne copie primaire.
Plusieurs systèmes tels que DEC , Grapevine et Clearinghouse ont préféré adopter des techniques moins restrictives pour réaliser les mises à jour des répertoires globaux, car ils estiment qu'elles sont peu fréquentes à ce niveau.
L'abandon de la contrainte d'atomicité a été la première concession faite dans ce sens, car celle-ci nécessite au préalable un accès sûre à toutes les copies. Chaque serveur qui reçoit une requête de mise à jour l'effectue sur sa copie locale, puis la propage vers les serveurs gérants des autres copies. Pendant cette phase, les clients peuvent accéder aux copies avec des contenus différents d'une manière indéterministe.
Avec de telles techniques les conflits de mise à jour sont possibles, mais on estime qu'ils sont peu probables. De plus, la manipulation des répertoires globaux est généralement réservée aux administrateurs du système, ce qui réduit encore la possibilité de conflit. Si toutefois un tel cas se présente, un ordre construit avec un mécanisme d'estampillage permet de régler les conflits, d'autres approches s'appuient sur les numéros de versions sont utilisées par Lampson et Daniels .
Étant donné que la propagation des mises à jour peut prendre du temps, le signalement des conflits est retardé jusqu'au moment où ils sont détectés. Un message est alors envoyé à l'administrateur pour l'aviser des modifications.
La performance est une qualité nécessaire pour les systèmes de grande taille,en effet, l'interconnexion des cellules par des réseaux globaux (WAN) affecte d'une manière significative le temps de réponse du système, et particulièrement son service de désignation qui vise le regroupement des espaces locaux à ces cellules.
Les caches de noms sont l'outil de base qui est utilisé pour améliorer les performances, ils constituent une forme de duplication destinée à accélérer la recherche de noms. La principale différence avec la duplication des répertoires est la persistance : le contenu du cache n'est que temporaire, de plus, les mises à jour de répertoires n'entraînent pas de mises à jour du cache mais une invalidation de ses entrées.
La propriété de localité des références à été observée dans l'exécution des programmes, ainsi que dans l'accès aux fichiers, et aux bases de données. Des études récentes ont été menées pour vérifier si cette propriété est vérifiée pour les noms symboliques ( voir K W Shirrif ). Le principe utilisé pour cette étude était de collecter, dans une première étape les noms fournis au service de désignation par les clients, et de les analyser dans une seconde phase. Les résultats se résument ainsi :
Dans les systèmes répartis, les techniques de cache sont appliquées à différents niveaux. Elles évitent aux clients de faire systématiquement des requêtes aux serveurs en conservant temporairement les résultats de requêtes antérieures. De telles techniques permettent d'accélérer la résolution des noms.
Dans les services de désignation de grande taille, les serveurs sont souvent organisés hiérarchiquement. La résolution des noms absolus commence d'abord par le serveur racine jusqu'aux serveurs fils, il est alors inacceptable du point de vue des performances de refaire une telle recherche à chaque fois. De plus, si le nombre de clients du service augmente, le serveur racine devient un goulot d'étranglement.
La mise en place de caches aux différents niveaux de la hiérarchie permet de réduire progressivement la charge des serveurs. Ces caches agissent comme des court-circuit vis-à-vis de l'arbre de désignation, ils permettent aussi une amélioration importante du temps de réponse.
Quand un cache est plein, un échec (miss) nécessite le remplacement d'une entrée du cache par une nouvelle, cette opération est généralement coûteuse car elle nécessite un chargement en mémoire du répertoire à partir du support de stockage. Deux techniques sont utilisées :
La distribution introduit de nouveaux problèmes pour l'usage des techniques de cache, les caches peuvent se trouver sur des sites différents. Si un répertoire est modifié, le contenu des caches risque de devenir inconsistant, une mise à jour par invalidation est alors nécessaire.
Il existe plusieurs techniques d'invalidation pour maintenir la cohérence des caches. Dans la suite, nous allons présenter celles qui s'adaptent le mieux aux noms symboliques.
La cohérence des caches de noms à base de délai de garde est utilisée dans plusieurs systèmes (DEC name service , Prospero etc..). Dans ces systèmes, les serveurs de noms associent à chaque entrée du cache une date de validité ( Time To Live ou TTL).
Le TTL varie en fonction des noms, il est généralement long pour les informations qui ne changent pas fréquemment (la racine par exemple), et court dans le cas contraire. Les clients cachent ces informations jusqu'à l'expiration du TTL. Pour éviter d'introduire des incohérences, la prise en compte des mises à jour de répertoires est retardée jusqu'à cette date.
Cette méthode souffre en conséquence d'une certaine rigidité de manipulation des répertoires, en plus les règles d'attribution des TTL ne sont pas clairement précisées. Le système NFS par exemple se contente d'une période d'invalidation fixe de trois secondes, si une modification a lieu, le contenu du cache est momentanément incohérent.

Fig 5. Mise en oeuvre des TTL dans le système DEC
L'exemple de la Fig 5 illustre la mise en oeuvre de ce principe dans le système DEC. Le résultat de l'opération de résolution de ANSI/DEC/SRC reste valide jusqu'au 15 Sept 1985 , qui est le minimum des deux valeurs rencontrées sur son chemin d'accès.
Un indicateur est une information qui peut potentiellement améliorer les performances du système si elle est correcte, dans le cas contraire, elle n'introduit aucune incohérence. Les stratégies à base d'indicateurs s'appliquent particulièrement aux informations ayant la propriété d'auto-validation, une simple opération sur leur contenu permet de déterminer leur validité.
Un fichier par exemple n'est pas un indicateur car son contenu ne révèle pas s'il est valide ou non. Par contre, l'association entre un nom d'objet et sa référence l'est, car il est possible de vérifier sa validité en faisant un test sur l'existence de l'objet.
Dans les systèmes où la modification d'un objet entraîne le changement de sa référence comme dans Amoeba, on doit prendre la précaution de gérer les versions des objets pour éviter d'introduire des incohérences. Une étude plus poussée sur l'utilisation des indicateurs est décrite dans Terry.
En utilisant les indicateurs comme information de cache, il est possible d'améliorer sensiblement les performances, de plus la propriété des indicateurs épargne une gestion, souvent complexe, de la cohérence du cache.
Dans les systèmes répartis, les indicateurs sont utilisés pour la localisation des fichiers, Sprite cache des correspondances entre des préfixes de noms et des adresses de serveurs, Andrew et Coda cachent des informations sur la localisation des volumes de stockage. Dans ces systèmes les clients utilisent ces informations pour leur requêtes jusqu'au moment où le serveur s'aperçoit qu'elle sont obsolètes, il fournit alors la nouvelle valeur de ces indicateurs aux clients qui les remettent à jour.
Apollo Domain utilise un serveur particulier (Hint Manager) pour gérer la cohérence des indicateurs, il étudie en particulier l'effet de la migration des fichiers sur la qualité des indicateurs.
Dans certains systèmes, le seul moyen de vérifier la validité de l'information du cache est de demander une confirmation aux serveurs l'ayant fournie. Cette opération peut être coûteuse si les répertoires sont distants, et particulièrement pour les données de petite taille ( tels que les noms ), car une nouvelle recherche s'avère alors plus avantageuse.
Une autre variante consiste à faire des liens inverses entre les répertoires et les caches, si un répertoire est modifié, les caches qui détiennent une copie sont rappelés pour invalider l'entrée correspondante.
Cette approche introduit un coût supplémentaire pour la gestion de ces liens, car le remplacement des entrées du cache, et la modification d'un répertoire nécessite leur mise à jour. Ces problèmes sont abordés dans la thèse de Sheltzer.