
La désignation est l'opération qui consiste d'une part à associer des noms aux objets, d'autres part à interpréter les noms des objets pour permettre leur accès.
Dans les systèmes répartis de grande taille, les aspects spécifiques suivants de la désignation sont à prendre en compte :
Dans ce chapitre nous allons présenter les notions de base de la désignation : les méthodes de structuration de l'espace de noms, et différents modèles de distribution du service de désignation. Puis nous illustrons sur différentes réalisations les notions de bases que nous avons dégagées.
Le fait de choisir d'écrire les noms d'une certaine manière constitue une adhésion à une convention de nommage. Une convention de nommage est un ensemble de règles qui définissent la correction syntaxique des noms.
Les conventions de nommage doivent être prises de manière à faciliter leur interprétation, cela permet d'augmenter la rapidité d'accès aux objets. En plus, elles doivent satisfaire une série de contraintes pour s'adapter à la répartition :
bullet La généralité : une convention de nommage doit permettre la désignation d'une grande variété d'objets. Il est important dans un système de permettre à un même objet d'être désigné par des noms différents soit par le même utilisateur soit par des utilisateurs différents.
bullet Le nommage multiple : c'est la possibilité de donner plusieurs noms au même objet.
bullet La distribution : Un nom doit être facilement fragmenté à travers les différents serveurs de désignation. Par exemple dans Unix, les noms absolus sont obtenus par concaténation des répertoires d'accès depuis le répertoire racine.
La propriété de transparence des noms est très recherchée dans les systèmes répartis, elle permet de cacher à l'utilisateur la distribution des ressources matérielles du système. Ainsi, au niveau logique l'utilisateur voit une machine virtuelle unique.
La transparence évite l'association statique d'un objet à un site, une machine ou un support de stockage particulier, donnant ainsi la possibilité de déplacer vers d'autres sites, d'autres machines ou d'autres supports du système.
Il existe plusieurs types de transparence à prendre en considération (cf. Kermarrec ) :
La majorité des systèmes d'exploitation utilise deux types de noms : des noms symboliques pour les utilisateurs et des noms internes (références systèmes) destinés à l'usage du système. L'intérêt de cette approche est de satisfaire les contraintes d'utilisation des noms :
Dans les systèmes existants, il y a deux approches différentes pour réaliser le service de désignation symbolique : une première approche intègre la fonction de désignation et la fonction d'accès dans un même service (généralement ce sont les systèmes répartis bâtis sur UNIX); et une seconde approche sépare ces deux fonctions en proposant un serveur pour la désignation et un autre pour le stockage (exemple : Sprite).
Un nom interne est une information destinée à l'usage interne du système, il permet d'identifier d'une manière unique une entité particulière du système. Les objets désignés par un nom interne sont très variés : on peut désigner des fichiers, des machines, des "ports" de communication, etc.
Les propriétés des noms internes sont les suivantes :
Un nom symbolique est une chaîne de caractères destinée à l'usage des utilisateurs, il permet de rattacher un sens aux noms des objets pour faciliter leur usage, il y a deux types de noms symboliques :
Les mécanismes de résolution adaptés à ces deux types de noms sont présentés dans la section 2.4.
La correspondance entre les noms symboliques d'objets et les identificateurs internes peut être réalisée au moyen d'une table d'entrées contenant des paires (nom symbolique, nom interne). Cette méthode bien que simple à implanter, ne permet pas une gestion efficace d'un grand nombre d'informations. En effet, l'efficacité des mécanismes de recherches et de mise à jour diminue proportionnellement à la taille de la table.
Pour résoudre ce problème, l'espace de noms est organisé sous forme de tables de petite taille (les répertoires), les répertoires eux mêmes sont désignés par des noms. Cette structuration introduit la notion de sous-répertoires qui permet la construction des espaces de noms.
L'organisation de l'espace de noms la plus utilisée est la structuration des répertoires en arbre, elle se prête bien aux besoins des utilisateurs pour regrouper les fichiers en fonction de leur utilisation, et s'adapte à l'organisation classique en hiérarchies des laboratoires et des entreprises.
Dans le cas des espaces de noms hiérarchiques, les noeuds de l'arbre sont de deux types : les noeuds terminaux qui sont les objets des applications, et les noeuds non terminaux qui correspondent aux répertoires.
Pour interpréter le nom d'un objet, les algorithmes de recherche parcourent l'arbre à partir d'un répertoire donné, en passant successivement par les différents répertoires qui conduisent à cet objet. La concaténation des noms de ces répertoires et celle du nom de l'objet est appelé chemin d'accès.
ex: /Bull/IMAG/Layaida/mail
Un chemin d'accès exprimé à partir de la racine est appelé nom absolu.
L'inconvénient de la structuration des répertoires en arbre se trouve au niveau de la racine, cette racine est un point de passage obligé des opérations de résolution de noms absolus, par conséquent elle forme un goulot d'étranglement. Pour éviter ce problème, on utilise la notion de noms relatifs et de contextes qui permettent une résolution de nom moins coûteuse.
Un nom relatif est un chemin d'accès qui est décrit relativement à un répertoire donné. En pratique, on utilise les notions de répertoire de travail (home directory) et de répertoire courant pour fabriquer des noms relatifs.
Un contexte est l'ensemble des répertoires qui peuvent être utilisés à un instant donné pour résoudre les noms relatifs écrits. En général, la racine de l'arborescence figure implicitement dans le contexte.
Les liens sont un moyen d'accéder plus rapidement à un objet ou à un répertoire, ils sont désignés par des noms et permettent de raccourcir la taille des noms absolus, ces derniers ayant tendance à se rallonger avec l'extension en hauteur de l'arbre de désignation. Il y a plusieurs types de liens :
Les liens permettent la construction de graphes quelconques à partir d'une structure d'arbre. Ils doivent être manipulés avec précaution pour ne pas engendrer de cycles, qui pourraient provoquer des boucles infinies dans le processus de résolution de noms (cf. Tanenbaum).
Un service de désignation global doit posséder un ensemble de qualités qui sont : la disponibilité, l'efficacité, l'extensibilité et l'adaptabilité à l'utilisateur.
La disponibilité est une qualité nécessaire pour un service de désignation. Le service étant un moyen d'accès aux objets, une défaillance de sa part entraîne un dysfonctionnement de tout le système. La disponibilité est obtenue par redondance, deux méthodes sont utilisées :
Dans les systèmes de grande taille, la distribution de l'espace de noms entraîne une dégradation du processus de résolution de noms. Pour pallier ce problème on utilise des caches de noms.
La disponibilité (à travers la tolérance aux pannes)et l'efficacité sont les qualités essentielles d'un service de désignation et, pour cette raison, font l'objet du chapitre III.
L'extensibilité d'un service de désignation se traduit par sa capacité à évoluer progressivement. Dans la vie d'un service de désignation réparti, on est parfois amené à réorganiser l'espace de noms global, cette opération intervient lorsque l'on souhaite réunir plusieurs machines ou sous-systèmes dans un même espace, ou qu'un changement dans l'organisation hiérarchique est décidé.
Dans le cas où les changements consistent à ajouter des entrées au niveau des répertoires existants, il n'y a aucun changement à apporter sur l'arbre de désignation. Dans le cas d'une extension vers le haut, ou d'une modification de la structure hiérarchique, la situation est plus complexe, ces deux derniers cas se traduisent par les opérations suivantes sur la structure de l'arbre :
Le problème introduit par cette réorganisation est de garantir la validité des noms symboliques déjà contenus dans le code des applications, car la structure des noms est modifiée. L'idée qui consiste à réécrire les noms existants est impossible du point de vue pratique, pour deux raisons :
Nous allons décrire par la suite les mesures qu'il faut prendre pour résoudre le problème dans chacun des deux cas précédents. Les mécanismes introduits nécessitent généralement un coût supplémentaire dans le processus de résolution de noms, de ce fait, ils sont généralement réservés aux répertoires du niveau global.
Le principe de cette opération est de créer un nouveau répertoire racine, et d'inclure les racines des espaces locaux aux sous-systèmes dans ce répertoire. Pour garantir la validité des anciens noms, on implante au niveau de la nouvelle racine une table de correspondance dont le rôle est de réaliser la correspondance entre les anciens et les nouveaux noms.
Pour réaliser cette correspondance, on ne peut pas se baser uniquement sur la syntaxe des noms car on risque d'avoir des conflits, il est donc nécessaire de pouvoir disposer d'une identification globale des répertoires. Dans le cas d'un espace de noms dupliqué, chaque identificateur doit caractériser l'ensemble des copies d'un même répertoire, le but est de pouvoir retrouver la racine correspondante à un nom global, il y a deux choix possibles :
L'identification des répertoires permet de retrouver le contexte de résolution d'un nom malgré les modifications de la structure de l'arbre global. Les requêtes de résolution de noms étant systématiquement envoyées vers la racine globale courante du système (ou vers l'une de ces copies), celle-ci se charge de réaliser la correspondance en fonction des identificateurs associés aux noms.
Pour identifier le contexte d'un nom donné ( ie. sa racine ), Lampson a introduit la notion de racine courante, son identificateur doit être ajouté à chaque nom global écrit par les applications.
Nom global = Id(Racine courante) + Nom symbolique
Par la suite d'une réorganisation dans la hiérarchie globale (disons qu'une firme informatique firme1 rachète une autre firme firme2 du même niveau hiérarchique), il est souhaitable de déplacer la sous-arborescence de firme1 au niveau de l'un des répertoires de firme2.
Le problème est le même que dans le cas de la création d'une nouvelle racine, il faut garantir que les noms restent valides malgré le changement de la structure des noms. Pour résoudre ce problème on utilise des liens de poursuite.
Ces liens de poursuite sont transparents aux utilisateurs du système, car ils sont utilisés uniquement pour les besoins internes du service de désignation, ils n'ont pas pas la même signification que les liens symboliques des utilisateurs dont le rôle est d'avoir des "raccourcis", et qui sont désignés explicitement comme des objets particuliers.
Avec la croissance de la taille des systèmes, il devient de plus en plus difficile pour les utilisateurs de se repérer dans l'espace de noms global. Il est alors souhaitable de fournir aux utilisateurs des outils de personnalisation de l'espace de désignation primitifnote1, en fonction des vues qu'ils veulent avoir. Ainsi, on peut cacher aux utilisateurs les parties de l'espace qui ne leur sont pas nécessaires.
Plusieurs techniques sont utilisées pour réaliser :
L'implantation de ces mécanismes se fait par l'adjonction d'une couche supplémentaire au dessus du service de désignation global.
La structuration du service de désignation varie d'un système à un autre, les modèles courants sont construits à partir de deux entités ayant des fonctions bien définies :
Pour rendre la localisation des objets totalement transparente à l'utilisateur, le service de désignation doit décharger l'utilisateur de l'identification des serveurs auxquels il doit envoyer ses requêtes (lookup). Cette transparence est réalisée au moyen d'agents de désignation qui sont les intermédiaires entre les clients et les serveurs, leurs rôles se résument en trois points :
Un agent peut appartenir à un seul ou à un groupe de clients, dans le premier cas, il est généralement implanté par un processus utilisateur, dans le second cas, il fait partie du noyau et l'interface de son utilisation est définie par un ensemble de primitives du système.
Les agents sont utilisés dans plusieurs systèmes avec des noms variés : resolvers dans le système dans DARPA Internet Domain, Grapevine User dans le système Grapevine, venus dans AFS.
Dans cette configuration, il n'existe qu'un seul serveur fournissant la totalité du service de désignation, cette solution est généralement adoptée par les systèmes qui disposent de serveurs de stockage à grande capacité, ces derniers étant centralisés, il n'y a aucune raison de répartir le service de désignation.
Bien que cette solution simplifie la gestion de l'espace de noms , elle présente les inconvénients suivants :
Le service de désignation de CSNET est un exemple de cette approche (cf. Solomon).
Pour réaliser la distribution du service de désignation, il est nécessaire de répartir l'espace de noms sur l'ensemble des serveurs. En général, l'espace est découpé en domaines hiérarchiques comme le montre la Fig 1 , chacun est géré par un serveur de désignation particulier et constitue un contexte de résolution de noms, on obtient ainsi une hiérarchie de serveurs. Il y a plusieurs choix possibles pour la distribution de l'espace de noms sur les serveurs de noms:
On trouve deux types de serveurs dans ce modèle, les serveurs du niveau local et les serveurs du niveau global. Dans les serveurs du niveau local, il n'y a que les noms des objets du domaine local qui sont visibles à une opération de désignation. Les objets externes au domaine ne peuvent être atteints que par la consultation préalable des serveurs du niveau global, ces derniers détiennent des informations sur la répartition de l'espace global (ie. des domaines) sur les différents serveurs locaux, leur rôle consiste à router les requêtes aux serveurs appropriés.
Il faut noter que la notion de nom d'objet local ou externe n'est pas fonction de la localité physique des objets, mais du découpage de l'espace de noms en domaines d'administration.
Il y a trois configurations construites à partir de ces deux catégories de serveurs et qui sont l'accès direct, indirect et la fédération.
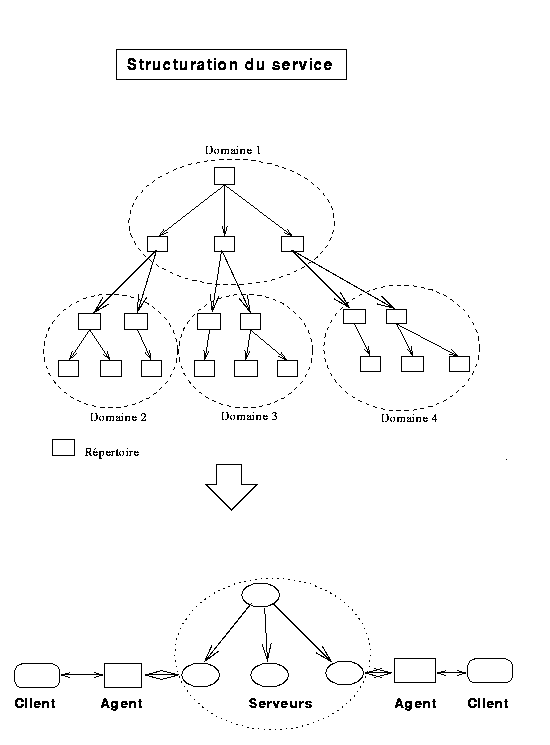
Dans cette configuration, un serveur local accède directement aux autres serveurs pour la résolution des noms externes à son domaine. Dans ce cas, il envoie une requête au serveur de noms global qui entame des recherches pour identifier le serveur gérantnote3 du nom, il remet ensuite son adresse au serveur local demandeur qui formule une nouvelle requête, cette fois-ci il l'envoie directement vers le serveur gérant.
Le serveur global agit donc comme un arbitre entre les serveurs locaux, son rôle consiste à orienter les serveurs locaux vers les serveurs gérants des noms.
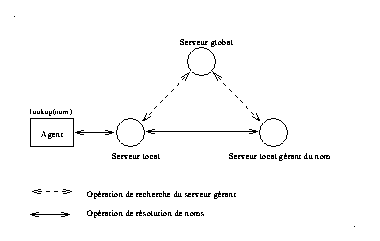
Dans ce modèle, le serveur global se charge entièrement de la résolution des noms externes aux serveurs locaux. Avant d'envoyer une requête, le serveur local vérifie que le nom est externe à son domaine, si c'est le cas, il envoie sa requête au serveur global qui s'occupe de sa résolution. Une fois cette opération terminée, le serveur global remet le résultat au serveur demandeur.
Dans cette approche, Il n'y a aucune communication entre les différents serveurs locaux, le serveur global joue le rôle d'intermédiaire entre les serveurs locaux.
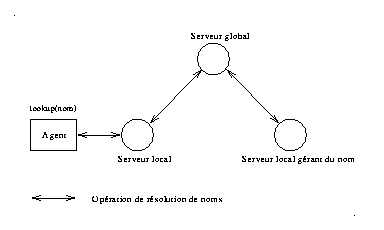
Dans cette approche, le serveur de noms global est distribué à travers les différents serveurs locaux, ces derniers forment ainsi une fédération de serveurs qui coopèrent pour réaliser le service global. Virtuellement, on parle de serveur fédéral défini par un protocole d'interaction entre les différents serveurs de la fédération.
Ce protocole est réalisé au moyen de mécanismes divers (diffusion, tables de préfixes etc ..). Chaque serveur doit implanter ces mécanismes pour adhérer à cette fédération. Dans ce cas, la notion de globalité est limitée aux membres de la fédération, notons aussi qu'un serveur peut faire partie de plusieurs fédérations.
La résolution de noms dans les systèmes distribués est une opération qui est réalisée en deux phases :
Il existe deux méthodes de résolution chacune adaptée à la nature des noms utilisés :
Les services de désignation utilisant des noms structurés s'appuient essentiellement sur la syntaxe des noms pour orienter l'opération de résolution, à chaque étape la partie du nom relative à un domaine permet de déterminer le serveur suivant, elle lui passe alors le reste du nom qui n'est pas encore résolu. La dernière étape est réalisée par le serveur gérant qui retrouve la référence de l'objet (voir Fig 5 ).
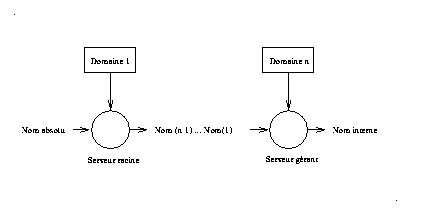
En pratique, il y a deux manières de retrouver un serveur à partir d'un nom.
Les espaces de noms dit "plats" sont les noms qui ne possèdent pas de structure interne, pour réaliser la distribution de l'espace de noms on utilise des techniques de groupements des noms en contextes. Les groupements sont définis à partir d'une condition (clustering condition ).
Une condition de groupement est une expression qui permet de partitionner les noms dans des contextes, l'application de cette condition sur un nom donné, permet de déterminer s'il appartient ou non à un contexte donné.
Il existe deux types de conditions de groupement :
Groupement par une fonction de hachage :
Dans cette approche, on utilise une fonction de hachage qui appliquée aux noms permet de déterminer leurs contextes. En général, on établit une correspondance entres les valeurs retournées par cette fonction et des numéros de contextes, chaque contexte étant implanté par un serveur différent.
Groupement par expressions régulières (Pattern matching) :
Dans cette approche, les contextes sont définis à partir d'expressions régulières, la correspondance entre un nom et son contexte est vérifiée au moyen de l'application de l'expression sur le nom (les expressions contiennent les symboles '*' et '?' classiques aux interpréteurs de commande d'UNIX)
ex: layaida vérifie l'expression l?y?i*
Ces deux techniques peuvent être appliquées plusieurs fois sur les noms, on obtient ainsi des contextes à plusieurs niveaux. Pour retrouver le contexte qui correspond à un nom donné, on utilise les fonctions qui ont permis de définir ces mêmes contextes. Ces techniques sont généralement utilisées pour les systèmes ayant un espace de noms à base d'attributs, la granularité des objets est relativement grande (machines , portions de réseaux, etc ..). Une étude détaillée est décrite dans Terry.
Les systèmes présentés apportent différentes solutions pour la construction d'un espace de noms global, ils sont classés en fonction de leur ordre chronologique, par la suite on présentera des systèmes ayant accordé un intérêt particulier à l'extensibilité.
Le système Unix United permet l'accès à des fichiers distants sur un ensemble de machines interconnectées par un réseau local. Chacune est dotée du système Unix. Ce système est le premier à proposer cette fonction d'où son intérêt historique. L'espace de noms de chaque site est organisé en arbre, pour construire une arborescence unique à tous les sites, on a ajouté une "super racine" notée /../ sur chaque site. Pour désigner un fichier à partir d'un site donné, on utilise deux syntaxes différentes. Si le fichier est local, le nom commence par le caractère '/', s'il est distant il est précédé par le symbole /../ et du nom du site où il se trouve.
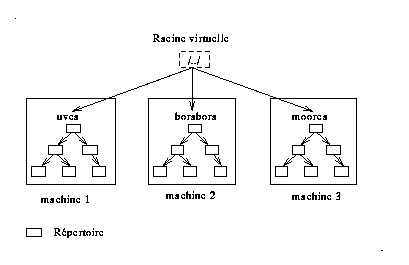
La réalisation de ce mécanisme d'accès à distance est effectuée au moyen d'une couche système au dessus d'Unix (Newcastle Connection). Les appels d'accès aux fichiers sont interceptés par cette couche qui les envoi aux serveurs des sites de destination, la communication entre les sites se fait par des appels de procédure à distance (RPC).
Dans cette approche, les noms de fichiers contiennent explicitement le nom du site de résidence, la transparence n'est donc pas assurée. Ce problème complique l'opération de migration des fichiers, car celle-ci nécessite la modification de tous les noms, pour résoudre ce problème, une solution consiste à utiliser des liens de poursuite mais le nombre de migrations se trouve alors limité.
Le système de gestion de fichiers d'NFS a pour objectif de fournir un mécanisme simple pour l'accès aux fichiers distants d'une manière transparente, dans ce cas la désignation et l'accès sont intégrés dans un même service.
Le montage de catalogues (mount) est utilisé comme opération de base pour regrouper les espaces de noms locaux aux machines. Il consiste à définir un point de montage dans les catalogues en lui donnant un nom, et de créer un lien de ce nom vers un catalogue situé sur un service de fichiers d'une machine distante. Une fois le montage effectué, l'accès au catalogue distant se fait de la même manière que l'accès aux catalogues locaux.

Dans NFS toute machine peut être à la fois serveur et client, il suffit qu'elle possède un disque pour pouvoir fournir aux autres machines un accès à son service de fichiers. L'espace de noms ainsi obtenu n'est plus forcement un arbre mais un graphe quelconque, ce graphe est construit à partir d'un ensemble d'arbres avec des liens particuliers (points de montage) formant des passerelles entre les espaces locaux. Pour éviter d'avoir des espaces de noms complexes on utilise des règles simplificatrices pour le montage, une règle courante est de monter partout le catalogue racine de toutes les machines sous le nom symbolique qui leur est attribué.
Certains systèmes utilisent des machines dédiées pour réaliser un tel service, donnant ainsi une vision plus globale des fichiers partageables, il suffit alors de faire un seul point de montage vers le catalogue racine de ce service pour avoir accès aux fichiers partagés. Les fichiers systèmes et ceux qui sont propres à une machine ne sont visibles que localement, cette méthode possède donc l'avantage de ne pas surcharger l'espace de noms.
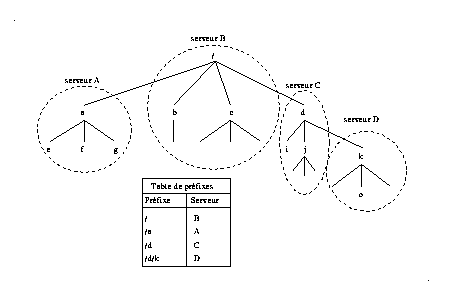
Les tables de préfixes sont un mécanisme simple pour l'implantation d'un espace de noms global uniforme et transparent. Elles permettent de décharger l'utilisateur de la gestion manuelle des points de montage introduite par NFS, l'idée consiste à utiliser des tables pour retrouver à partir d'un nom le serveur correspondant.
Chaque client du système maintient à son niveau une table de préfixe, cette table est formée d'une association entre des préfixes de noms et des adresses de serveurs, chaque serveur gère une partie de l'arborescence global (un domaine). L'accès à un fichier consiste, dans une première étape à localiser le serveur gérant, cette opération est réalisée en recherchant dans la table le plus long préfixe du nom. Ensuite, le suffixe est envoyé au serveur correspondant qui réalise l'accès effectif.
Cette méthode nécessite des mécanismes de construction et de mise à jour des tables adaptés a leur forte activité de coopération, le mécanisme de diffusion a été donc une solution appropriée. Cette méthode est à la base des système Sprite, Locus et V-System.
Ce mécanisme apporte plusieurs avantages par rapport à ceux utilisant une hiérarchie de serveurs :
bullet Le client gère lui même l'espace de noms, il n'est pas nécessaire d'implanter un service de noms séparé.
bullet La reconfiguration est simple à réaliser, il suffit de modifier les entrées des tables.
bullet La possibilité d'avoir des stations sans disque local car la table est construite dynamiquement.
Un exemple pour illustrer ce principe est donné dans la Fig 8 , il y a quatre domaines gérés par trois serveurs, le plus grand chemin trouvé pour un nom donné détermine le serveur qui va résoudre le nom ex: le nom de fichier /d/k/o est résolu par le serveur D.
Le principal inconvénient de cette méthode est son inadaptation à l'extension, le nombre d'entrées dans la table augmente proportionnellement au nombre de sites du système, par conséquent la recherche dans la table devient très coûteuse. En plus, on ne peut regrouper les sites en cellules, car il n'existe toujours pas de mécanisme fiable pour réaliser une diffusion inter-cellule. Cette solution reste donc destinée aux réseaux locaux où le nombre de sites n'est pas très grand (une centaine environ).
Les systèmes présentés ici ont accordé un grand intérêt à l'extension, l'objectif de chacun est de proposer un service de désignation regroupant un grand nombre de machines.
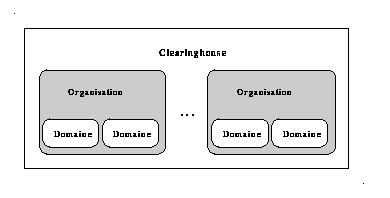
Clearinghouse est un service de désignation réparti qui constitue une amélioration des premières versions de Grapevine . Il est utilisé principalement pour nommer les boîtes aux lettres, les utilisateurs et les serveurs. L'espace de noms de Clearinghouse est géré par un ensemble de serveurs, chaque serveur prend en charge une portion de l'espace global. Les noms sont organisés en arbre à trois niveaux pour limiter la complexité des algorithmes de recherche. Un nom a la forme suivante (L:D:O), ils correspondent respectivement au nom local, au nom du domaine et au nom de l'organisation, cette désignation est uniforme dans l'ensemble du système (la syntaxe du nom ne dépend pas du site où il est écrit).
A chaque objet Clearinghouse est associé un ensemble de propriétés, chacune est un triplet ordonné < Nom de propriété, Type, Valeur >, le Type spécifie le format de la Valeur. Il y a deux types de propriétés : un objet chaîne de bits (qui ne sont pas interprétés), et un objet groupe qui est une liste de noms.
L'avantage de cette désignation est de pouvoir nommer les objets sans se préoccuper de leur type, l'objectif étant de pouvoir désigner une grande variété d'objets. Paradoxalement c'est aussi son inconvénient : si un nouveau type est introduit dans l'espace de noms, les utilisateurs doivent être avisés de sa sémantique pour pouvoir l'exploiter.
V-System est un projet de recherche à l'université de Stanford, le but est d'explorer la mise en oeuvre d'un système réparti basé sur les stations de travail. Le service de désignation est structuré hiérarchiquement en trois niveaux (global, administratif et local). Chaque niveau est caractérisé par des besoins spécifiques de performances, de sécurité et de degré de résistance aux pannes Cheriton et Mann,. Cette découpe de l'espace de noms a conduit les concepteurs à utiliser trois techniques pour implanter les répertoires, chacune adaptée au niveau de la hiérarchie correspondant (cf. Fig 10 ).
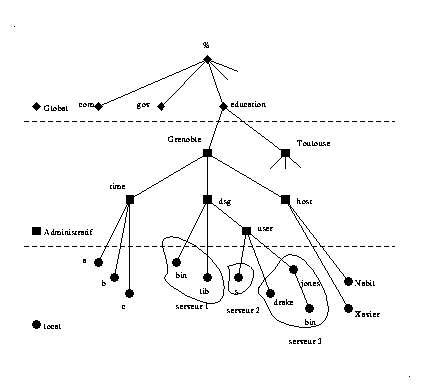
L'espace de noms est un arbre unique et transparent à base de répertoires dupliqués sur un ensemble de serveurs. Pour identifier le serveur gérant des répertoires, la résolution de noms utilise un protocole de diffusion de groupes (multicast), la propagation de cette diffusion est réalisée de proche en proche, elle commence à partir du serveur local en direction des serveurs les plus lointains, à chaque étape le groupe de serveurs est élargi. Pour implanter cette diffusion progressive, on utilise la notion de groupes de proximité (nearby groups).
La recherche de noms termine lorsque l'un des serveurs du groupe répond à la demande. Dans le cas où plusieurs serveurs répondent (ceux qui possèdent une copie du répertoire), les réponses en trop sont ignorées. Cette approche offre un niveau élevé de résistance aux pannes, au prix d'une surcharge importante du réseau. Pour limiter le coût de la recherche, on utilise des caches de préfixes de noms. L'implantation de ce système est décrite en détail dans la thèse de T.P Mann .
Ce système a été développé dans le centre de recherche de DEC . L'objectif de ce système est de pouvoir regrouper un nombre potentiellement illimité de machines, distribuée à travers le monde. L'espace de noms global est organisé hiérarchiquement.
Le principal apport de ce système est la flexibilité des opérations de regroupement de sous-systèmes et de réorganisation. Pour ce faire, l'espace de noms peut être étendu par le haut en créant une nouvelle racine, et la structure de l'arbre peut être modifiée en déplaçant un sous-arbre d'un endroit vers un autre. Dans les deux cas la validité des anciens noms est garantie.
La disponibilité est réalisée au moyen de la duplication des répertoires globaux, les copies sont placées sur différents endroits du système pour résister aux pannes. La cohérence des copies de répertoires au niveau global est maintenue par un protocole de cohérence faible, ce choix vise à tenir compte des délais de communications et du faible taux de modification de ces répertoires.
L'ambition de départ de ce système était de désigner des objets de grande granularité (par exemple les machines, les utilisateurs et les boites aux lettres), par la suite un prototype a été réalisé pour nommer les fichiers.
Le système AFS (Andrew File System) a été développé à l'université Carnegie Mellon (CMU), l'objectif était d'exploiter les premières stations de travail parus sur le marché, chaque étudiant avait accès à une station supportant le système UNIX. La particularité de ce système est sa taille (environ 10 000 stations interconnectées).
La configuration du système est un ensemble de cellules interconnectées par un réseau local, chaque cellule est constituée d'un ensemble de stations de travail et d'un serveur de fichier. Cette idée vise à réduire le trafic sur le portion du réseau qui permet l'interconnexion des cellules (voir Fig 11 ).
L'espace de noms de chaque cellule est construit à l'aide de la notion de volumes, un volume est un espace de stockage muni de l'arborescence des noms des fichiers qu'il contient. Chaque utilisateur (pour des raisons de protection) est affecté à une cellule, et utilise l'espace de stockage (volume) d'une station particulière. Une règle simple est utilisée pour définir l'espace de noms global à une cellule : tous les répertoires d'une station montés sur le serveur de fichier central sous le répertoire /CMU sont visibles aux autres utilisateurs, le reste des répertoires ne sont que locaux, les stations utilisent une interface particulière (venus) pour dialoguer avec le serveur central (vice).
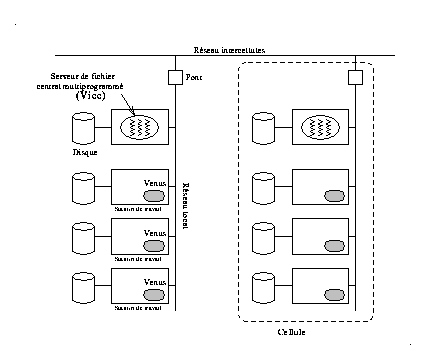
L'espace de noms est un arbre global à l'ensemble des cellules, le service de désignation est implanté par les serveurs (vice) qui utilisent les points de montage pour former l'arbre. AFS traite aussi le problème de mobilité des utilisateurs sur le réseau en fournissant un mécanisme élaboré de cache de fichiers.
Bien que le service de fichiers d'AFS ait atteint ses objectifs, l'approche de l'extension pour la désignation est basée sur l'utilisation de gros serveurs, par conséquent les techniques utilisées ne peuvent se généraliser aux systèmes où les composantes matérielles sont homogènes (c.a.d il n'y a pas de serveur de désignation dédié).
ce terme désigne le serveur responsable de la gestion du domaine du nom